From pain to pleasure: rethinking data entry
With any digital project which involves the capture of information from analogue sources, there are two possible approaches. For projects like Old Bailey Online or London’s Pulse, where a single body of source material exists and is readily accessible, automated or outsourced mass digitisation (using OCR, rekeying, or a combination) is practical and effective. But where primary materials are disparate, widely distributed, and require mediation, ‘data entry’ is an inevitable – and frankly a rather depressing – part of the process.
Let’s face it: no matter which way you cut it, transcribing and rekeying information is never going to be an exciting or creative activity. It’s a laborious, tedious, and manual process. Equally, in the context of a project like ours, it is a job which can’t simply be devolved. Synthesising information together from multiple sources calls for archival experience, and the academic expertise to know how to interpret the material you are looking at.
All of which adds up to the prospect of a long three years' work for the project team.
Let's make things better
For the KCL Digital Humanities team this is an interesting challenge and it is something I’ve been researching and exploring myself in a number of different contexts for a while now. Our department has numerous research projects running at the moment in various stages of completion. For a long time we have standardised on using a flexible and powerful web application framework called Django for projects where – as with Redress of the Past – we anticipate working with structured data (i.e. where we need to record many different types of regular or ‘tombstone’ information for each pageant – such as where it was performed, by whom, when, how much tickets cost, and so on).
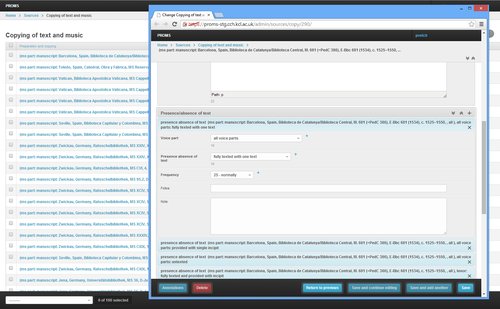 Normally we would create an appropriate database structure to
store this information, and then use Django’s administrative interface to
create a set of data entry forms for the research team to use. The problem with this is that often these
forms end up being very complex and unwieldy to use (as you can see!). Academics are as digitally engaged as anyone
else, and for most people, free-form data entry into Microsoft
Word or Evernote is often the most comfortable and idiomatic way of capturing
data digitally. Complex forms impose
structure, which we need - but also add a lot of cognitive overload, and their inherent lack of flexibility often causes frustration or mistakes.
Normally we would create an appropriate database structure to
store this information, and then use Django’s administrative interface to
create a set of data entry forms for the research team to use. The problem with this is that often these
forms end up being very complex and unwieldy to use (as you can see!). Academics are as digitally engaged as anyone
else, and for most people, free-form data entry into Microsoft
Word or Evernote is often the most comfortable and idiomatic way of capturing
data digitally. Complex forms impose
structure, which we need - but also add a lot of cognitive overload, and their inherent lack of flexibility often causes frustration or mistakes.
For this project we want to try something different. The challenges are:
- Can we deliver an environment for data entry
that is actively fun and easy to use?
- Can we create some workflows for data entry that
will help out the project team by doing some of the work automatically for them?
- Most importantly: can we transform data entry into an activity that actually contributes positively to the research process?
"A little bird told me..."
We’ve begun tackling the first of these challenges (and hopefully laid a solid foundation for the rest) by adopting a rather smart and brand new mobile first Open Source CMS (content management system) called Wagtail, which was developed by Oxfordshire-based web agency Torchbox for the Royal College of Art's new website. Wagtail has been designed with a focus on improving user experience for editors, and on providing a solid basis for the sort of custom development work that most projects need. For us, a big attraction is that Wagtail is built on our framework of choice; it’s a Django app and we can therefore extend, adapt, and plugin to it however we like. So, we can take its great user interface principles and conventions for web content editing and extend them to a very different problem: capturing information from archives.
We began by modelling the project team’s preliminary data capture form (a Microsoft Word document), in Wagtail. Despite the fact that this had some 50 fields (some structured, some not) and can contain over 7,500 words of information, we have been able to use Wagtail's interface to create a single page form which allows all the data for a given pageant to be captured in one place – no more popups or multiple screens. We can still impose structure where we need to, but for the research team the work of entering data will be much more painless, and much less obtrusive. Where an archive offers an internet connection data can be entered directly into the system via a tablet or laptop; where there's no internet data can be captured on the Word proforma and imported into Wagtail with formatting and links preserved.
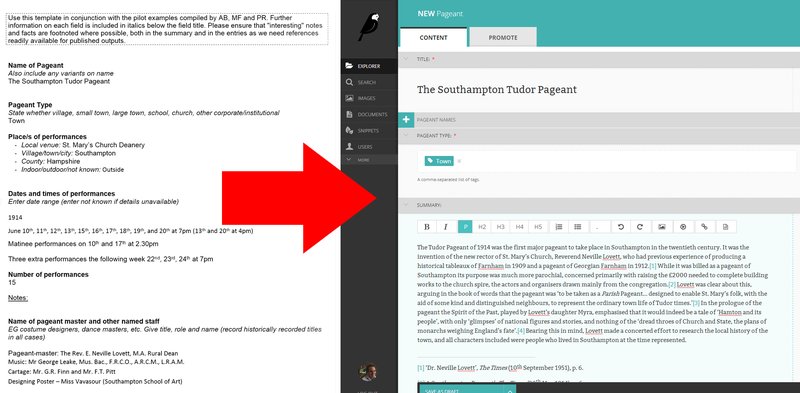
Now, we're working on adding some additional cleverness. In my previous blog post I talked about the importance for our users of capturing information about people in the pageants; we’re now working on tailoring Wagtail to automatically recognise not only people, but also places, music, and bibliographic references automatically as the research team enters their data, to help speed things up.
Watch this space ( - and give Wagtail a look!)